Traditional inference: every request goes to a GPU data center, regardless of task complexity or user location. You pay for reserved capacity even when it’s idle. ZeroGPU: requests run on a distributed network of edge devices — laptops, phones, servers, browsers — using Nano Language Models that don’t need GPUs.Documentation Index
Fetch the complete documentation index at: https://docs.zerogpu.ai/llms.txt
Use this file to discover all available pages before exploring further.
Why centralized inference is expensive
| Problem | Cost |
|---|---|
| Traffic spikes | Over-provision GPUs or accept latency spikes |
| Oversized models | LLMs consume GPU resources for tasks that don’t need them |
| Regional egress | Data round-trips to distant data centers add latency and fees |
| Idle capacity | Reserved instances cost money 24/7 |
How ZeroGPU distributes it
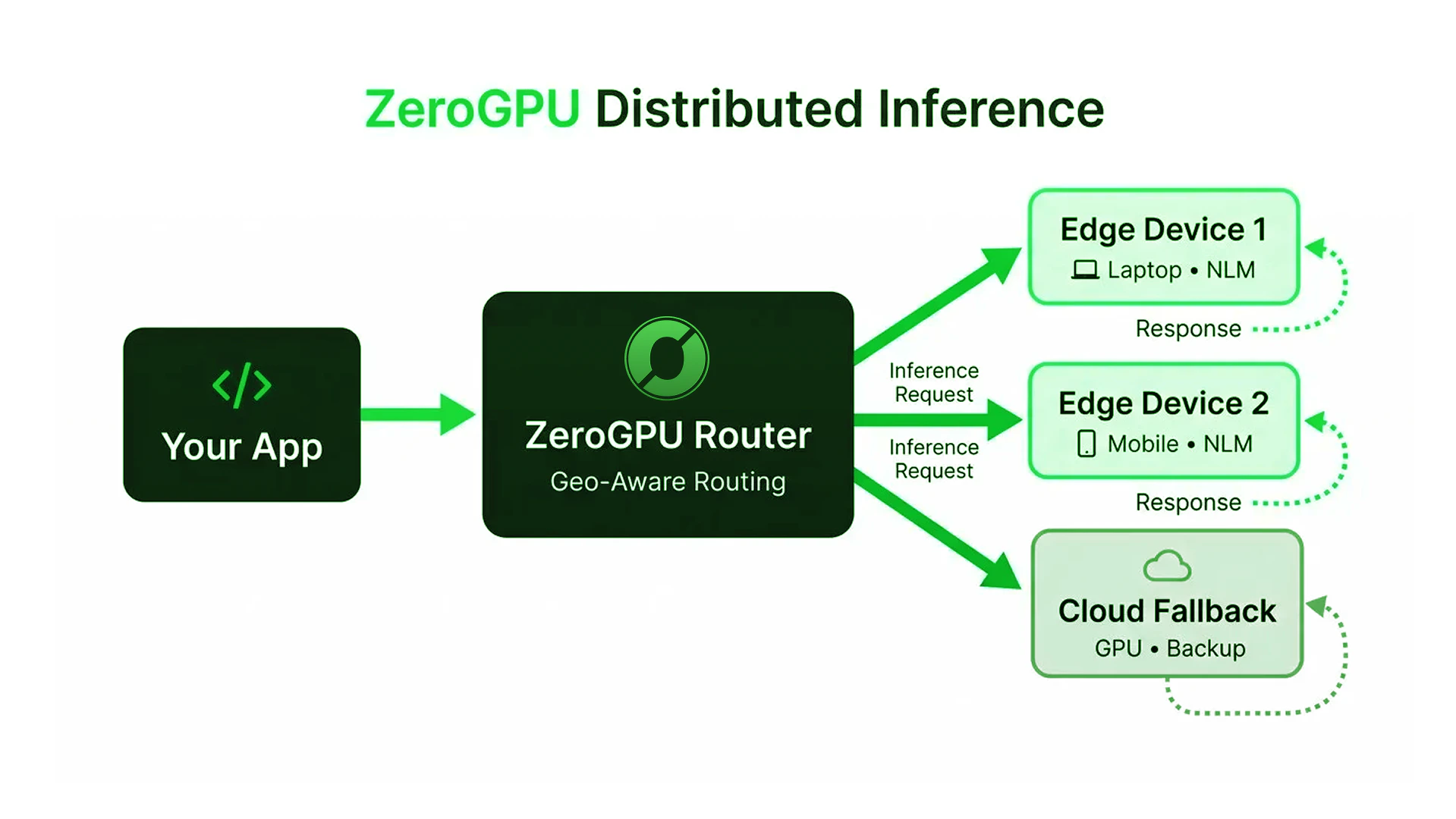
- Your app sends a request to ZeroGPU
- Router picks the best edge node by location, capacity, and model availability
- Edge device runs the NLM and returns the result
- Cloud fallback catches requests when no edge node is available
What you get
- Scale horizontally — more devices = more capacity, no GPU procurement
- Pay for usage — not reserved instances sitting idle
- Lower latency — inference runs near the user, not across the country
- Resilience — no single point of failure; traffic reroutes automatically
Geo-Aware Routing
How the router picks the optimal node.
Quickstart
Send your first distributed inference request.